Projekt Indywidualny
Marcin Wudarczyk
Grupa C
3. Znalezienie najkrótszych ścieżek łączących każdą parę checkpointów *
4. Aproksymacyjne rozwiązanie problemu komiwojażera dla grafu checkpointów *
Minimalne drzewo rozpinające *
5. Przechodzenie przez wszystkie checkpointy, aż któryś zostanie zabezpieczony *
6. Sprowadzenie poprzedniego rozwiązania do nowej sytuacji *
class map : public dynarray2<word> *
class movmapobj : public mapobj { *
class robomap : public movmap { *
class roboobj : public movmapobj { *
class checkpoint : public mapobj { *
1. Format przechowywania mapy *
Znajdowanie najbliższego nieodwiedzonego wierzchołka (robo::nearestunvis) *
4. Znajdowanie najkrótszych ścieżek między wszystkimi checkpointami *
5. Znajdowanie minimalnego drzewa rozpinającego *
7. Sprowadzanie drzewa do nowej sytuacji *
Zadanie
Mamy siatkę prostokątną o zadanym rozmiarze (większy bok ma n kwadratów jednostkowych - dalej zwanych pixelami). Każdy pixel może mieć jeden z następujących stanów: pusty, wypełniony, jest na nim przynajmniej jeden obiekt. Należy wygenerować w sposób losowy labirynt - tj. ustawić stany każdego pixela na pusty lub wypełniony. Następnie losowo rozmieścić na mapie zadaną ilość tzw. checkpointów, które są obiektami. Każdy checkpoint ma swój numer, numer mieści się w zakresie od 0 do k-1, gdzie k to liczba checkpointów. Następnie do mapy wstawiamy robota (też jest obiektem). Zadaniem robota jest przejście przez wszystkie checkpointy w zadanej kolejności (rosnących numerów checkpointów), nie znanej robotowi. Robot może zapamiętywać dowolne informacje o mapie, ale tylko o pixelach, na które wszedł, ma te informacje.
Operatory mają takie same znaczenie, jak w języku C++. W szczególności, operator == oznacza równość, [] odwołanie do indeksu tablicy. Inne użyte pojęcia są zwykle definiowane w miejscu użycia, lub też są ogólnie znane i przyjęte, np. stos, wektor, kolejka FIFO. W razie niejasności należy się odwołać do książki "Algorytmy i struktury danych", której jednym z autorów jest prof. Diks. Ściana jest to pixel oznaczony jako zapełniony, czyli taki, na który obiekt nie może wejść. Pixel jest to twór, na którym może stać obiekt. Mapa składa się z pixeli.
Przykładowy kod oraz definicje klas zostały napisane w języku C++.
Ogólny schemat postępowania programu:
Operacja ta będzie przebiegała w następujący sposób:
Łamana składa się z uporządkowanych krawędzi. Krawędzie są odcinkami prostymi złożonymi z pixeli z stanem ściana. Każda następna krawędź położona jest w stosunku do poprzedniej pod kątem P /2. Każda następna krawędź ma dokładnie jeden punkt wspólny z każda inną krawędzią, położony na jej początku lub końcu i będący jednocześnie ostatnim lub pierwszym punktem poprzedniej krawędzi.
Parametrami będą:
W tej części dokumentu będziemy mówić, że pixel sąsiaduje ze ścianą wtedy i tylko wtedy, gdy przynajmniej jeden z ośmiu pixeli przylegających do niego ścianami lub wierzchołkami jest ścianą (izolowana pixel-ściana nie sąsiaduje ze ścianą).
Łamana sąsiaduje ze ścianą, gdy jeden z pixeli do niej należących sąsiaduje ze ścianą nie należącą do aktualnie generowanej łamanej.
W trakcie postępowania pamiętamy w zmiennej (znacznik), czy generowana łamana sąsiaduje ze ścianą.
Oto algorytm generowania krawędzi:
Ilość i parametry wrzucanych łamanych do mapy będą ustalane przez użytkownika.
Nie będzie to przeszukiwanie w głąb, ponieważ wracanie po ścieżce, po której się doszło do pixela jest nieefektywne. Dlatego należy szukać najkrótszej drogi do dowolnego nieodwiedzonego pixela. Zauważmy, że w ten sposób przechodzimy całą mapę.
Będą również specjalne zasady, w której robot będzie wybierał sąsiadów pixela, na którym jest, do przejścia. Oczywiście to nie ma większego znaczenia, ponieważ nie istnieją takie zasady, która dla każdego labiryntu dawałaby optymalne przejście mapy (przy założeniu, że robot nie zna mapy).
Stworzymy nowy hipotetyczny graf (w odróżnieniu od grafu, w którym wierzchołkami są pixele), w którym wierzchołkami będą spójne grupy pixeli sąsiadujących, leżących w równej odległości od punktu początkowego (z którego robot zaczyna przeszukiwanie) w metryce maksimum. Wierzchołkami będą więc grupy leżące na koncentrycznych kwadratowych pierścieniach o szerokości jednego pixela. Grupy te muszą być spójne - w szczególności oznacza to, że można przejść robotem całą grupę nie przechodząc przez żaden pixel nie należący do grupy.
Należy zwrócić uwagę, że aby być wierzchołkiem, nie trzeba być maksymalną spójną grupą leżącą na tym samym pierścieniu. Natomiast graf tworzymy tak, że każda maksymalna grupa pixeli o wyżej wymienionych właściwościach składa się z co najwyżej dwóch wierzchołków nowego grafu.
Powyższe wynika z założenia, że robot zawsze przechodzi przez pixele należące do wierzchołka nowego grafu za jednym zamachem (czyli nie schodzi z grupy, dopóki wszystkie jej pixele nie będą odwiedzone, oraz do przejścia grupy potrzebuje dokładnie tyle ruchów, ile jest w grupie pixeli). Dlatego też, jeżeli robot wejdzie na maksymalną spójną grupę nie na jednym z jej końców, to dzieli ja na dwa wierzchołki nowego grafu.
Robot trzyma w swojej pamięci mapę, na których zaznacza odwiedzone pixele oraz ściany, na które się natknął.
Robot postępuje według następującego schematu:
Teoretyczne oszacowanie złożoności takiego algorytmu przedstawia się następująco. Każdy pixel będzie przechodzony dokładnie raz, oprócz przesunięć do najbliższego nieodwiedzonego pixela.
Oznaczenia:
n - rozmiar boku mapy w pixelach
p - liczba szukań najkrótszej drogi
p = o(n2), ponieważ mamy o(n2) wierzchołków tego hipotetycznego grafu (ścian oddzielających te wierzchołki, których możemy szukać jest też o(n2)), i dla każdego wierzchołka szukamy drogi co najwyżej raz (bo szukamy do nieodwiedzonego pixela, ale potem on już będzie odwiedzony). Oczekiwana wartość będzie zapewne mniejsza.
Liczba ruchów robota: o(n2 + p*n) = o(n3)
Złożoność obliczeniowa: o(n2 * p) = o(n4)
Możemy także do problemu oszacowania podejść inaczej: zauważmy, że takie przeszukiwanie jest w miarę izomorficzne z przeszukiwaniem w pewnej kolejności w głąb naszego hipotetycznego grafu. Ponieważ liczba jego wierzchołków i krawędzi jest równa o(n2), to chociaż złożoność obliczeniowa dalej wynosi o(n4), to udało nam się ograniczyć liczbę ruchów robota do o(n2).
Powstaje pytanie, jaka jest zasadność użycia szukania najkrótszej drogi, które podnosi bardzo złożoność algorytmu (przy przeszukiwaniu w głąb mamy o(n2)), a właściwie nie obniża pesymistycznej ilości ruchów robota. Zależy to od różnicy pomiędzy czasem wykonania jednej operacji obliczeniowej a czasem przesunięcia robota. Jeżeli np. robot jest na komputerze zdalnym, wtedy opłacalne jest minimalizować liczbę ruchów nawet kosztem o(n2) operacji lokalnych w każdym ruchu.
Zadanie jest następujące: mamy zadane dwa punkty na mapie. Mamy znaleźć najkrótszą ścieżkę je łączącą. Ścieżka nie może zawierać pixeli zajętych przez ściany.
Chyba standardowy algorytm w tej sytuacji, będący uproszczoną wersją algorytmu Dijkstry: przeszukiwanie wszerz grafu pixeli, i wpisywanie w każdy wierzchołek długości najkrótszej drogi wiodącej do źródła (początkowego pixela szukanej drogi). Oczywiście długość najkrótszej drogi do źródła dla pewnego pixela jest równa minimalnej długości tej drogi dla sąsiadów pixela (dół, góra, lewy, prawy) plus jeden. Przeszukujemy wszerz, dopóki nie będziemy rozpatrywać pixela docelowego.
Następnie należy uzyskać ścieżkę. W tym celu zaczynamy w punkcie docelowym. Zapamiętujemy go jako koniec ścieżki i ustawiamy jako aktualnego. Teraz wybieramy tego sąsiada aktualnego pixela, który ma najkrótszą drogę do źródła (czyli sprawdzamy, który sąsiad ma najmniejszą wartość poprzednio wyliczonego atrybutu) i ustawiamy go na aktualnego. Wrzucamy go na ścieżkę przed poprzednio wrzuconym pixelem Kontynuujemy, podczas gdy aktualny pixel nie jest źródłem.
Oczywiście całe przeszukiwanie odbywa się na mapie zapamiętanej przez robota. Robot w tym czasie się nie porusza. Złożoność obliczeniowa jest równa o(n2)
Gdy szukamy drogi do najbliższego nieodwiedzonego wierzchołka, robimy podobnie jak poprzednio, tylko przeszukujemy wszerz, gdy nie napotkamy na pierwszy nieodwiedzony pixel. Ponadto najpierw należy sprawdzić 2 sąsiadów: na zewnątrz pierścienia i wewnątrz pierścienia, czy któryś z nich jest nie odwiedzony. W takim wypadku (który będzie dość częstym przy przeszukiwaniu mapy) pomijamy przeszukiwanie wszerz i przesuwamy robota na znaleziony punkt.
Wykonujemy ten krok, aby potem móc znaleźć odpowiednią ścieżkę przechodzenia.
W pewnej kolejności dla każdego checkpointa wykonujemy
Złożoność obliczeniowa tego kroku to o(n2q) (q - liczba niezabezpieczonych checkpointów).
Ponieważ w ogólności problem komiwojażera jest np-zupełny, stosujemy rozwiązanie aproksymacyjne. Polega ono na:
Skonstruowane drzewo zapamiętujemy.
W praktyce nie będziemy szukali ścieżki poprzez przeszukiwanie w głąb, a potem jej przechodzili, tylko będziemy ją konstruować w trakcie chodzenia robotem.
Zastosujemy algorytm Kruskala. Przedstawia się on następująco:
Przy tym algorytmie stosuje się specjalną strukturę danych (drzewa z kompresją ścieżek), która pozwala uzyskać złożoność obliczeniową całego algorytmu równą o(q2 log q).
Robot aktualnie stoi tam, gdzie go ostatnio zostawiliśmy, czyli na jednym z checkpointów. Rozpoczynamy przeszukiwanie w głąb właśnie od tego checkpointa. Przesuwamy robota po zapamiętanych ścieżkach. Przeszukiwania w głąb nie będę opisywał (patrz "Algorytmy i Struktury Danych", Diks i inni). Można zastosować pewne usprawnienie podczas przeszukiwania (w wersji iteracyjnej): gdy zdejmujemy ze stosu następny checkpoint do przejścia, możemy przejść do niego robotem bezpośrednio (mamy zapamiętaną ścieżkę, a nie wracać po krawędziach, po których przyszliśmy, jak w wersji rekurencyjnej)
Złożoność obliczeniowa tego etapu wynosi o(qn). Robot musi wykonać co najwyżej 2*(suma wag krawędzi minimalnego drzewa rozpinającego) ruchów, czyli o(qn). Gdy w końcu zabezpieczymy jeden z checkpointów, zapamiętujemy ten fakt, i przystępujemy do następnej fazy.
Teraz potrzebujemy powtórzyć postępowanie z poprzedniego punktu: przejść wszystkie niezabezpieczone checkpointy. Musimy znaleźć w miarę minimalną ścieżkę, przechodzącą przez wszystkie rozpatrywane checkpointy (czyli te co poprzednio oprócz ostatnio zabezpieczonego). Sztuka polega na tym, aby wykorzystać rozwiązanie dla poprzedniego grafu.
Usunięcie tego checkpointa z minimalnego drzewa rozpinającego spowodowało rozspójnienie drzewa. Mamy teraz pewną ilość spójnych składowych, które trzeba połączyć. Więc teraz potraktujemy je jako wierzchołki nowego grafu, w którym będziemy szukać minimalnego drzewa rozpinającego. Wagami krawędzi między dwiema składowymi będzie minimalna waga krawędzi łączących te dwie składowe (czyli krawędzi incydentnych z wierzchołkami jednocześnie z jednej i drugiej składowej).
W wyniku znalezienia tego drzewa jesteśmy w stanie skonstruować nowe drzewo rozpinające grafu niezabezpieczonych checkpointów złożone z krawędzi poprzedniego drzewa checkpointów pomniejszonego o zabezpieczony wierzchołek, a powiększonego o krawędzie grafu checkpointów odpowiadające krawędziom minimalnego drzewa rozpinającego spójnych składowych, znalezionego w poprzednim kroku.
Aby podzielić drzewo na składowe, wykonujemy przeszukiwanie w głąb, zapamiętując dla każdego wierzchołka, do której składowej należy. Potem dla każdej pary wierzchołków z różnych składowych sprawdzamy, czy zapamiętana odległość składowych jest mniejsza od wagi aktualnej krawędzi, i ewentualnie ją aktualizujemy. Na początku odległości między składowymi inicjalizujemy na +nieskończoność.
Ogólnie złożoność obliczeniowa tej fazy wynosi o(u2 * log u + q2), gdzie u to liczba składowych, na które dzieli się minimalne drzewo rozpinające po usunięciu ostatnio zabezpieczonego wierzchołka.
Możemy spróbować oszacować złożoność q-krotnego powtarzania kroku 6, czyli sprowadzania minimalnego drzewa rozpinającego dla coraz mniejszej liczby wierzchołków. Złożoność pojedynczego kroku tej fazy jest o(u2 * log u + q2). Składnik q2 nie będzie się istotnie zmieniał, więc po q-krotnym wykonaniu otrzymamy o(q3), natomiast rozważenia wymaga całkowita liczba składowych, które trzeba rozważyć. Pesymistycznie, każde usunięcie jednego checkpointa z drzewa może stworzyć graf izolowanych wierzchołków. Wtedy mamy całkowity koszt o(q3 * log q). Jednak ze względu na specyfikę grafu checkpointów (np. dla każdych trzech parami różnych wierzchołków jest spełniona nierówność trójkąta) wydaje mi się, że czas oczekiwany będzie mniejszy.
Złożoność obliczeniowa całego algorytmu chodzenia robota przedstawia się następująco: o(n4 + k3 * log k). Przy założeniu, że liczba checkpointów jest proporcjonalna do długości boku mapy, mamy ostateczną złożoność pesymistyczną o(n4).
Liczba ruchów robota można ograniczyć przez o(n2 + k2n). I tutaj oczekiwana ilość przesunięć powinna być mniejsza. Dla liczby checkpointów o(n), mamy ilość ruchów robota o(n3).
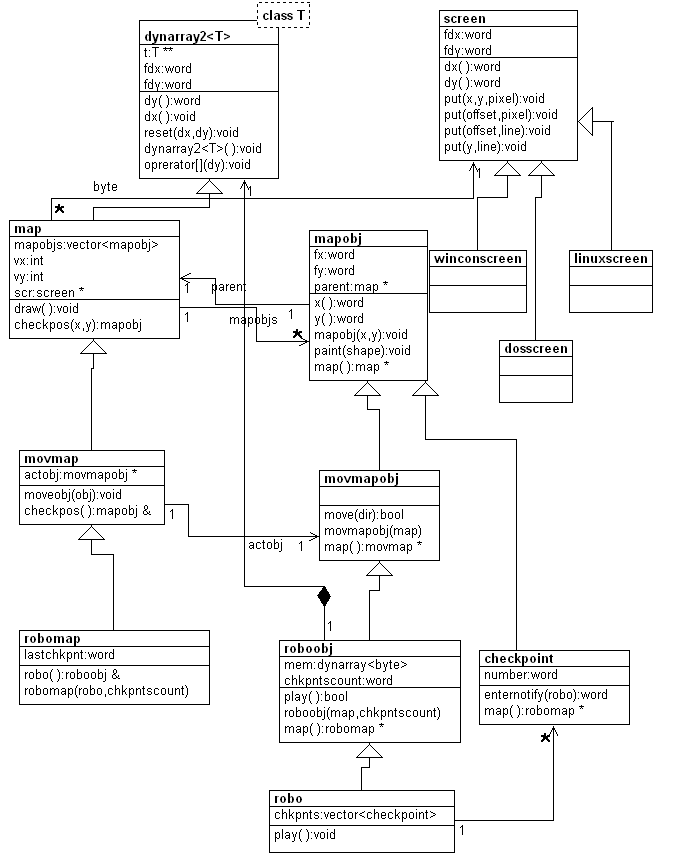
Podstawowe klasy to:
Rysunek znajdujący się poniżej prezentuje podstawowe relacje pomiędzy klasami. Nie należy brać atrybutów tych klas uwidocznionych na rysunku uważać za wiążace. Wiążace są definicje klas.
Dalej są definicje klas (w C++). Nie ma deklaracji wszystkich funkcji składowych - są tylko ważne dla modelu (mające znaczenie dla powiązań między klasami i obiektami). Inne należy dodać samemu.
typedef unsigned char byte;
typedef unsigned short word;
typedef unsigned long dword;
template <class T>
vector<T> {private:
T *t;
word s;
public:
void reset (word size);
// ustawia nowy rozmiar, wszystkie poprzednie dane są tracone
void resize (word size);
// ustawia nowy rozmiar, dane są kopiowane
vector () : t(0), s(0) {}
vector(word size) t(0) { reset(size); }
~vector() { delete [] t; }
word size() const { return size; }
T &oprerator[](word i) const { return const_cast<T&>(t[i]); }
operator T*() const { return const_cast<T&>(t); }
};
template <class T>
dynarray2<T> {private:
T ** t;
word fdx; // rozmiar tablicy
word fdy;
public:
dynarray2() : t(0) {}
dynarray2(word dy, word dx);
~dynarray2() { if (t) delete t[0]; delete t; }
// alokuje pamięc pod tablicę o rozmiarze dy na dx
private:
/* out-of-line */ void alloc(word dy, word dx) {
t = new T* [dy];
t[0] = new T[dx*dy];
for(word i=1; i<dy; ++i)
t[i] = t[i-1] + dx;
}
public:
word dy () const { return fdx; }
void dx () const { return fdy; }
void reset (word dy, word dx);
// ustawia nowy rozmiar, wszystkie poprzednie dane są tracone
void resize (word dy, word dx);
// ustawia nowy rozmiar, dane są kopiowane
T* oprerator[](word dy) const { return t[dy]; }
T& operator()(dword offset) const { return *t[offset]; }
};
template <class T>
class dynhalfarray2<T>;
/* to samo co dynarray2, tyle, że tylko dolny trójkąt macierzy, bez diagonalii (trzeba zmienić pętlę w alloc) */
class
mapobj; map : protected dynarray2<word>{
protected:
vector<mapobj *> mapobjs; // lista obiektów na mapie
word vx; // pozycja pierwszego wyświetlanego pixela na mapie
word vy;
word sx;
word sy;
word sdx;
word sdy; // pozycja i rozmiar okna na ekranie, w którym będzie wyświetlana mapa
screen * scr;
public:
class plotter; // public, bo screen musi o nim wiedzieć
map() : dynarray2<byte>(), scr(0) {}
map(word dx, word dy, screen *s) : dynarray2<byte>(dx, dy), scr(s), vx(0), vy(0) {}
~map(); // delete'uje mapobj'e, zamyka scr
//obiekty
inline void insobj(mapobj *);
inline void delobj(mapobj *); // usuwa z mapobjs i delete'uje
// rysowanie
void draw() {
scr->put(plotter(this));
}
inline void setclip(word sx, word sy, word sdx, word sdy);
inline void setpos(word vx, word vy);
inline screen::attr getattr(word offset); // zwraca atrybuty pixela o offsecie, z mapobjami
};
mapobj {
friend map;
protected:
word fx;
word fy;
map &parent; // mapa, na której znajduje się obiekt, nie można zmienić
private:
public:
void mapobj (word x, word y, map &parent) : fx(x), fy(y), parent(&parent) { }
virtual ~mapobj() { }
word x() { return fx; }
word y() { return fy; }
virtual attr paint() =0;
map &map() const { return parent; }
};
movmap : public map {
protected:
mapobj* actobj; // wskażnik na obiekt, który powinien być zawsze widzialny
word delta; // minimalna odległość actobja od krawędzi ekranu
public:
enum direction { up, right, down, left };
~movmap() ; // należy usunąc actobj
void adjust(); // zapewnia, że actobj jest widzialny
void setactobj(mapobj *actobj); // ustawia actobj i odświeża widok
void setdelta(word); // ustawia delta
bool moveobj(movmapobj *, direction dir); // porusza obiekt, wywołuje adjust
void checkpos(mapobj *) const; // zwraca obiekt, który jest w pierwszej warstie, na tym polu co argument, lub 0
virtual void draw(); // także rysuje actobj
};
class movmapobj : public mapobj {
public:
movmapobj(word x, word y, movmap *parent) : mapobj(x, y, parent) {}
movmap &map () const { return static_cast<movmap &>(parent); }
protected:
typedef movmap::direction direction;
bool move(direction dir) { return map().moveobj(this, dir); }
// porusza obiektem, jeżeli udało się ruszyć, i tylko wtedy, zwraca true, przerysowje mapę
mapobj *checkpos() const { return map().checkpos(this); } // zwraca mapobj, który znajdue się na aktualnej pozycji lub 0
};
robomap : public movmap {
private:
word secchkpntcount;
word chkpntscount;
void checkednotify(checkpoint *); // ta funkcja powinna być wywoływana po zabezpieczeniu checkpointa, implementacja aktualizuje zmienne składowe
friend void checkpoint::enternotify(const roboobj &co);
public:
robomap (roboobj *robo, word dx, word dy, screen *scr);
bool allchecked() const { return secchkpntcount == chkpntscount; }
bool generatecheckpoint(word tries);
/* próbuje tries razy losować pozycję na mapie. Sprawdza, czy na niej jest pusty pixel. Jeżeli tak, ustawia tam checkpointa i wychodzi. Zwraca true ó udało się wstawić checkpointa */
inline word checkpointscount() const; // zwraca liczbę checkpointów
inline word seccheckpointscount() const; // zwraca liczbę zabezpieczonych checkpointów
};
roboobj : public movmapobj {protected:
inline word checkpointscount() const; // zwraca liczbę checkpointów
inline word seccheckpointscount() const; // zwraca liczbę zabezpieczonych checkpointów
// odczytuje ze skojarzonego obiektu klasy robomap
/* zabezpiecza checkpoint na aktualnej pozycji. Zwraca true, jeżeli został zabezpieczony. W parametrze co zwraca checkpoint na aktulanej pozycji lub 0, jeżeli nie ma. */
inline bool securecheckpoint(/* out */ checkpoint *&co) {
mapobj *t = checkpos();
if (t && dynamic_cast<checkpoint *>(t))
return (co = ((checkpoint *)t))->enternotify(this);
else {
co = 0;
return false;
}
}
/* jeżeli nie ma rtti w kompilatorze (dynamic_cast<>()), to należy zrobić virtualna funkcję zwracającą id typu w klasie mapobj, i na jej podstwaie dokonywać konwersji. */
public:
roboobj(word x, word y, robomap &parent) : movmapobj(x, y, parent){}
robomap &map () const { return static_cast<robomap &>(parent); }
};
checkpoint : public mapobj {
private:
word number;
public:
roboobj(word x, word y, robomap &parent, word number) : movmapobj(x, y, parent), number(number) {}
int enternotify(const roboobj &robo); // informuje checkpoint o wejściu nań robota, ale powinien to sprawdzić, zwraca -1 jak jeszcze nie został zabezpieczony, jak został to swój numer
robomap &map () const { return static_cast<robomap &>(parent);
};
robo : public roboobj {
private:
struct edge;
vector<byte> mem; // mapa pamiętana przez robota, jej rozmiar poziomy i pionowy jest dwa razy większy niż rzeczywistej mapy, po zakończeniu przeszukiwania mapy
vector<checkpoint *> chkpnts; // przechowuje wskażniki do już odkrytych i niezabezpieczonych checkpointów; indeks w tej talicy jednoznacznie identyfikuje checkpointa
word unsecchkpntscount; // liczba niezabezpieczonch checkpointów po przeszukaniu mapy
dynhalfarray2<path> paths; // przechowuje ścieżki pomiędzy checkpointami
vector<word> visited;
tree t;
stack<word> s;
/* funckja przechodzi od jednego checkpointa do drugiego po znalezionej ścieżce w tablicy paths. Aby nie trzymać dwóch kopii jednej ścieżki (od checkpointa x do y i odwrotnej), chodzimy po ścieżkach od tyłu. */
inline bool gotocheckpoint(word source, word dest) {
if (dest < source)
return gotopath(paths[source][dest]);
else if (dest > source)
return gotorevpath(paths[dest][source]);
else
return true;
}
// zwraca odległość między checkpointami
inline word delta(word source, word dest) {
if (dest < source)
return paths[source][dest].size();
else if (dest > source)
return gotorevpath(paths[dest][source].size();
else
return 0;
}
public:
void play ();
inline robo(word x, word y, robomap &parent);
/* klasa rysująca mapę, mówi obiektowi screen, co ma rysować */
map::plotter {private:
map *m;
dword baseoffset;
public:
plotter(map *m, dword baseoffset) : m(m), baseoffset(baseoffset) {}
screen::attr operator()(word offset) const { return m->getattr(baseoffset + offset); }
};
screen {private:
word fdx; // rozmiar ekranu w pixelach
word fdy;
public:
struct attr {
char ch; // znak
byte cl; // kolor
attr(ch, cl): ch(ch), cl(cl) {}
};
word dx() const { return fdx; }
word dy() const { return fdy; }
virtual bool open();
virtual void close()
virtual void put (word y, word x, attr pixel) // wypełnia podany pixel podanymi atrybutami
/* template<class plotter>
virtual void put(dword offset, word count, plotter &) =0;*/
virtual void put(word y, word x, word count, map::plotter &) =0;
// używa class function plotter do wyrysowania mapy
clear(); // czyści ekran
};
class dosscreen : public screen {
public:
};
class winconscreen : public screen {
public:
};
class linuxscreen : public screen {
public:
};
typedef vector<direction> path;
template<class T>
class queue : public vector<T> {
/* ukrywa kolejkę fifo, implementacja tablicowa */
private:
word beg; // index tego elementu tablicy, który jest pierwszy do zdjęcia
word end; // index tego elementu tablicy, w którym się powinno dostawić nowy element
public:
typedef vector<T> inherited;
queue();
queue(word size);
ins(const T &co);
T pop();
T *begin() { return *this+beg; }
}
Drzewo z dowiązaniami do ojca i kompresją ścieżek
Ta struktura jest wykorzystywana przy znajdowaniu minimalnego drzewa rozpinającego. Jej celem jest efektywne przechowywanie pewnych elementów podzielonych na zbiory, szybkie wyszukiwanie, czy dwa elementy należą do tego samego zbioru, i szybkie łączenie dwóch zbiorów w jeden.
class mintreedata {
private:
struct node {
word parent; //to jest indeks w tablicy nodes, gdzie jest ojciec tego elementu
};
vector<word> sizes; // rozmiary zbiorów
vector<node> nodes;
public:
void init(word count); // tworzy count nodeów w oddzielnych zbiorach, które otrzymują kolejne numery (od zera), alokuje i ustawia sizes na 1,
word find(word data); // znajduje setid
void union(word setid1, word setid2);
};
void mintreedata::init(word count);
Alokuje count node'ów w nodes, ustawia ich parent na 0xFFFF. Alokuje count wordów w sizes, ustawia każdy element na 1.
word mintreedata::find(word data);
Zwraca pewną liczbę jednoznacznie identyfikującą zbiór, do którego należy node o kluczu data. Odbywa się do w dwóch przebiegach: najpierw idziemy kolejno po nodach, zaczynając od node[data], potem node[node[i].parent] itd., aż do node'a takiego, że node[i].parent == 0xFFFF. Wtedy indeks tego node'a jest identyfikatorem zbioru.
W drugim przebiegu zaczynamy znowu od node[data] itd., i ustawiamy każdemu node'owi parenta na indeks tego node'a na poprzedniej ścieżce, którego parent == 0xFFFF.
void mintreedata::union(word setid1, word setid2);
Ta funkcja łączy dwa zbiory. Ściśle rzecz biorąc podłącza szczytowy node mniejszego z tych zbiorów do szczytowego node'a większego (node jest szczytowy, gdy jego parent == 0xFFFF, dla każdego zbioru istnieje dokładnie jeden node szczytowy należący do niego).
Na początku sprawdzamy rozmiary zbiorów w tablicy sizes - będą to sizes[setid1], sizes[setid2]. Dla ustalenia uwagi załóżmy że podłączamy setid2 pod setid1. Więc wystarczy wykonać nodes[setid2].parent = setid1. Potem trzeba jeszcze zaktualizować rozmiar w tablicy sizes.
Złożoność operacji union jest o(1), a find o(n log*n), gdzie log*n jest funkcją odwrotną do funkcji Ackermanna. Inicjalizacja w czasie liniowym.
W trakcie postępowania musimy pamiętać drzewo. Można w tym celu użyć zwykłej reprezentacji listowej, jednakże ze względu na liniową ilość krawędzi można to zrobić nieco sprawniej.
class tree {
public:
struct edge {
word v; // indeks checkpointa
word n; // indeks nastepnej krawędzi w tablicy krawędzi, 0xFFFF oznacza koniec
};
vector<edge> edges;
vector<dword> firstedges;
operator const edge*() const { return edges; }
edge operator[](word co) const { return edges[co]; }
private:
word firstempty; // indeks pierwszej wolnej krawędzi
public:
tree();
tree(word count); /* alokuje count w firstedge i 2*count+2 w edges, ustawia firstempty na 0, ustawia wszystkie elementy firstedge na 0xFFFF, z elementów edges tworzy jedną dużą listę */
void insedge(word source, word dest);
void deledge(word source, word dest);
void delvert(word index); // kasuje wierzchołek
};
Implementacja listy jest na tablicy edges. Koniec jest zaznaczony przez 0xFFFF. Utrzymywana jest lista nieużywanych elementów na jej początek wskazuje firstempty. Na początku wszystkie elementy powinny się znajdować na tej liście. Potem, w miarę dodawania nowych krawędzi, zdejmujemy z listy pustych elementów pierwszy z nich i dodajemy go na początku wybranej listy sąsiedztwa.
Każdy wierzchołek ma przechowywane początek listy. Jest to indeks w tablicy edges pierwszego sąsiada. Te dane są przechowywane w tablicy firstedges. Wartość 0xFFFF oznacza, że nie ma sąsiada.
Operację wstawiania już opisałem, usuwamy według wszelkich reguł list jednokierunkowych, zwolniony element tablicy edge należy podłączyć na początku listy pustych elementów.
Jeżeli kasujemy wierzchołek, to należy podłączyć całą jego listę sąsiedztwa na początku listy pustych elementów, a wcześniej trzeba usunąć go z list sąsiedztwa wszystkich jego sąsiadów.
Uwaga - będziemy rozpatrywać drzewo nieskierowane, więc jeżeli dodajemy krawędź {a, b}, to należy wykonać insedge(a, b); insedge(b, a). Tak samo przy usuwaniu krawędzi.
Program główny będzie wyglądał tak:
A tutaj mamy funkcję robo::play.
Format przechowywania mapy
Mapa jest przechowywana w obiektach klasy map w postaci dwuwymiarowej tablicy elementów typu word. Każdy z takich elementów trzyma informację o jednym pixelu. Wartość 0 oznacza wolne nieodwiedzone pole, 1 ścianę, 2 puste odwiedzone pole, zaś każda większa wartość oznacza, że na tym polu jest jeden obiekt 0 - to implikuje, że to pole było już odwiedzone. W tym wypadku po odjęciu od wartości 3 otrzymujemy indeks w tablicy map::mapobjs, pod którym przechowywany jest ten obiekt znajdujący się na tym polu, który ma najmniejszy indeks w tej tablicy. Mapa ma maksymalne rozmiary 32000 na 32000 pixeli. Maksymalna liczba checkpointów również wynosi 32000.
Na początku zerujemy mapę i otaczamy ścianami.
Proces generowania łamanych będzie ukrywać funkcja:
void map::generatepoly(word vertprob, /* odpowiada prawdopodobieństwu końca krawędzi - podajmey liczbę dziesięciotysięcznych żądanego prawdopodobieństwa. (p = vertprob/10000)*/
word orientprob, /* odpowiada prawdopodobieństwu kierunku innego niż orientacja - podajmey liczbę dziesięciotysięcznych żądanego prawdopodobieństwa. (p = vertprob/10000)*/
bool orientclockwise /* jeżeli true, to orientacja zgodna z kierunkiem ruchu wskazówek zegara */
);
Treść funkcji jest opisana w sekcji Algorytmy.
Losowe ściany wstawia funkcja
void map::generatewall();
Po prostu losuje pozycję na mapie, i jeżeli na niej nie ma ściany, to ją ustawia.
Robot przechowuje swoją mapę (robo::mem), która jest czterokrotnie większa od oczekiwanych rozmiarów mapy. Dla każdego pixela jest przechowywana wartość typu byte. Wartość 0 oznacza nieodwiedzone pole, wartość jeden ścianę, wartość 2 odwiedzone pole. Na początku tablica mem powinna być wypełniona zerami.
Przeszukiwanie mapy odbywa się w funkcji:
bool robo::searchmap();
Funkcja ta zwraca true, gdy znaleziono wszystkie checkpointy i false, gdy nie udało się ich znaleźć mimo przeszukania całej mapy. Postępuje według algorytmu z sekcji przeszukiwanie mapy.
W trakcie swego działania funkcja wywołuje funkcję
bool robo::nearestunvis(/* out */path &co) const;
która znajduje najbliższy nieodwiedzony pixel, zwraca do niego ścieżkę w zmiennej co i zwraca true, gdy udało się ją znaleźć.
Również użyteczna będzie funkcja
bool robo::gotopath(const path &co);
która przesuwa robota wzdłuż podanej ścieżki. Jeżeli w którymś momencie przeszkodziła ściana, to zwraca false. Ścieżkę należy usunąć, jak już będzie niepotrzebna, przez wywołanie reset(0). Funkcja ta przesuwa robotem używając funkcji move.
Funkcja searchmap powinna zapamiętać znalezione niezabezpieczone checkpointy w tablicy chkpnts oraz ustawić ilość niezabezpieczonych checkpointów.
Znajdowanie najbliższego nieodwiedzonego wierzchołka (robo::nearestunvis)
Na samym początku sprawdzamy dwóch sąsiadów naszego wierzchołka, czy nie są puste i nie odwiedzone. W takim wypadku wybieramy jeden z nich, jak w algorytmie, i zwracamy do niego ścieżkę.
Na początku tworzymy kolejkę FIFO przechowującą pozycje pixeli (y, x) i wstawiamy pozycje aktualnego pixela. Kolejka musi pomieścić maksymalnie 8*max(rozmiar mapy pionowy lub poziomy)+4. Tworzymy dodatkową tablicę delta o takich rozmiarach jak robo::mem i wartościach word. Inicjalizujemy ją na wartość 0xFFFF. W punkcie odpowiadającym aktualnym współrzędnym wstawiamy 0. Poprzez wartość 0xFFFF oznaczamy wierzchołek, który jeszcze nie był w kolejce.
Następnie powtarzamy dopóki kolejka nie jest pusta:
Po wyjściu z tej pętli albo dostaniemy najbliższy nieodwiedzony pixel (on będzie aktualnym), albo okaże się, że kolejka jest pusta i wtedy wychodzimy z funkcji zwracając false.
Jeżeli dostaliśmy pixel, to teraz musimy skonstruować do niego drogę. Znamy jej długość, więc rezerwujemy odpowiednią ilość elementów w parametrze co.
Teraz będziemy wracać do punktu początkowego, zapamiętując ścieżkę od tyłu. Na początku pewien indeks wskazuje na ostatni element tablicy co, a potem po każdym obrocie pętli będzie on dekrementowany.
Poprzednika pewnego pixela leżącego na szukanej ścieżce będziemy identyfikować po minimalnym atrybucie delta. Inaczej mówiąc, szukamy tego z sąsiadów bezpośrednich, który ma najmniejszą wartość delta, kierunek, w jakim trzeba iść z tego pixela do aktualnego zapamiętujemy w tablicy co, i zmieniamy pixel aktualny na ten nowy, minimalny. Postępujemy tak, aż aktualny pixel będzie miał delta = 0.
Powyższe postępowanie zamykamy w funkcji
void robo::genpath(const dynarray2<word> &t, word y, word x, path &co);
t jest tą pomocniczą tablicą, (y, x) pozycją znalezionego pixela, a w parametrze co funkcja powinna zapamiętać ścieżkę.
Wychodzimy z funkcji z wartością true.
Będzie to robić funkcja
void robo::findpaths();
Wypełnia ona tablicę paths odpowiednimi danymi.
Na początku należy ustawić rozmiar tablicy paths na równy ilości znalezionych niezabezpieczonych checkpointów. Trzeba również stworzyć tablicę delta jak w sekcji Znajdowanie najbliższego nieodwiedzonego wierzchołka. W tablicy paths przechowujemy najkrótsze ścieżki między checkpointami. W elemencie (i, j) tej tablicy znajduje się ścieżka od checkpointa, który ma indeks i w tablicy robo::chkpnts do checkpointa o indeksie j.
Dla każdego checkpointa o indeksie w tablicy chkpnts różnym od zera będziemy postępować następująco:
Zauważmy, że możemy traktować rozmiar tablicy paths[i][j] jako odległość między checkpointem i a j.
No i to już koniec. Zwalniamy tymczasową pamięć i wychodzimy z funkcji. Tablica mem będzie już niepotrzebna.
W funkcji
void robo::findmintree();
szukamy minimalnego drzewa rozpinającego algorytmem Kruskala. Do przechowywania informacji o spójnych zbiorach wierzchołków używamy struktury opisanej wcześniej. Potrzebujemy również posortować wszystkie krawędzie. W rzeczywistości będziemy sortować pary liczb określające początkowy i końcowy checkpoint - wszak możemy dla nich otrzymać klucz - czyli odległość. Wrzucamy wszystkie podzbiory dwuelementowe zbioru {1, ..., liczba niezabezpieczonych checkpointów} do wektora, sortujemy quicksortem (z medianą z trzech i nie tym wbudowanym w C++, bo to kosztowna część algorytmu).
Właściwa implementacja powinna się znaleźć w funkcji
struct robo::edge {
word source;
word dest;
};
void robo::kruskal(word count, const vector<edge> &edges, const dynhalfarray<edge> *trans, tree &t);
count to liczba wierzchołków grafu, w edges mamy posortowane krawędzie grafu, trans jest wskaźnikiem na macierz przekształceń krawędzi (będzie potrzebne później - jeżeli przekazane jest 0, to nie ma żadnej translacji), zaś t to wynikowe drzewo - do niego algorytm powinien dodawać krawędzie drzewa. Funkcja powinna założyć, że drzewo jest już zainicjalizowane.
Tworzymy obiekt klasy mintreedata i inicjalizujemy na liczbę niezabezpieczonych checkpointów. No i teraz mając to wszystko możemy postępować według stosownego algorytmu opisanego w części algorytmu.
Jeżeli znaleźliśmy już krawędź należąca do drzewa, to dokonujemy translacji (jeżeli trans != 0). Chodzi o to, aby w drzewie połączyć inne wierzchołki niż te, które wynikają z edge'a w tablicy edges. Więc jeżeli {a, b} to krawędź znaleziona w tablicy edges, b<a, i spełnia założenia krawędzi co do dodania do drzewa, to do t wsadzamy krawędź {trans[a][b].source, trans[a][b].dest}. Jeżeli trans==0, to wsadzamy po prostu {a, b}.
Funkcja robo::findmintree powinna wywoływać funkcję robo::kruskal z parametrem trans równym zero. Pozostałe struktury powinna ona stworzyć, jak również powinna posortować krawędzie według wag.
word robo::traversetree(word chkpnt);
Jak już pisałem wcześniej, przechodzimy drzewo w głąb. W tym celu potrzebujemy stos (rekurencyjne wywołania funkcji składowych zajmują 8 bajtów plus parametry). Przecież stos można łatwo zrobić na tablicy wordów o rozmiarze równym liczbie wierzchołków. Oprócz tego musimy pamiętać dla każdego wierzchołka, czy był już na stosie - w wektorze wordów o nazwie visited.
Jeżeli stos lub tablica visited ma rozmiar równy zero, to ustawiamy odpowiedni (równy ilości rozpatrywanych checkpointów).
Na początku inicjalizujemy wektor visited na 0. Przechodzenie zaczynamy od podanego checkpointa. Wrzucamy go na stos, i aktualizujemy wektor visited.
No a teraz to już jak to przechodzenie w głąb - zdejmujemy checkpointa ze stosu przechodzimy tam robotem (używając gotopath i tablicy paths), jeżeli go zabezpieczyliśmy, to wychodzimy z pętli, zwracając jego indeks w tablicy chkpnts.
Teraz musimy dodać wszystkich nieodwiedzonych i nie będących jeszcze na stosie sąsiadów zdjętego wierzchołka na stos - przechodzimy po kolei listę sąsiedztwa dla naszego wierzchołka i aktualizujemy wektor visited po wrzuceniu checkpointa na stos. Powtarzamy całość, dopóki nie zabezpieczymy sobie jakiegoś checkpointa.
Przed wyjściem z funkcji nie usuwamy stosu, drzewa ani tablicy visited.
void robo::domintree(word chkpnt);
Najpierw usuwamy wierzchołek z drzewa. Teraz musimy oznaczyć spójne składowe. W tym celu przechodzimy graf w głąb. Tym razem trochę inaczej. W pętli. Używamy znowu stos i wektor visited. Tym razem w visited przechowujemy id składowej. Wartość 0xFFFF oznacza nieodwiedzony wierzchołek. Na ta wartość inicjalizujemy ten wektor.
I teraz kolejno dla każdego wierzchołka: jeżeli jest on nieodwiedzony, to: ustaw numer aktualnej składowej na równy dotychczasowej liczbie znalezionych składowych, zwiększ liczbę składowych o jeden, dla tego wierzchołka wykonaj przeszukiwanie w głąb.
Podczas przeszukiwania nie chodź robotem, ale ustawiaj wartości w tablicy visited na numer aktualnej składowej wtedy, gdy ją aktualizowałeś. Nie wyskakuj z przechodzenia - przechodź, dopóki stos nie będzie pusty.
Po zakończeniu przechodzeniu wróć do pętli i szukaj znowu nieodwiedzonego wierzchołka. Oczywiście nie należy inicjalizować znowu tablicy visited.
I już. Mamy podzielony graf.
Teraz odległości między składowymi. Tworzymy dwie półtablice dwuwymiarowe - jedna typu word - tam będą odległości między składowymi, a druga typu robo::edge - tu będą krawędzie odpowiadające tym odległościom łączące dwie składowe o numerach odpowiadających wierszowi i kolumnie. Każda z tych tablic powinna mieć wymiary równe liczbie składowych.
Mając te tablice, przeglądamy wszystkie krawędzie (tj. całą tablicę paths), sprawdzamy, do jakich składowych należą końce aktualnej krawędzi, jeżeli do różnych, to sprawdzamy, czy długość ścieżki jest mniejsza od wagi krawędzi łączącej odpowiednie składowe w tablicy odległości składowych. Jeżeli tak, to aktualizujemy tą wartość i krawędź w tablicy krawędzi.
Następnie wywołujemy robo::kruskal dla grafu składowych - najpierw musimy posortować krawędzie łączące składowe po wagach - tworzymy wektor i quicksort. Jako parametr trans przekazujemy naszą tablicę krawędzi, jako drzewo obiekt, który dotychczas był drzewem.
T *t;
Trzyma wskaźnik na dynamiczną tablicę.
word s;
Zawiera rozmiar tablicy.
void reset (word size);
Ustala nowy rozmiar tablicy na size, kasuje poprzednie dane.
void resize (word size);
Ustawia nowy rozmiar, dane są kopiowane.
vector () : t(0), s(0) {}
Inicjalizuje zmienne składowe na 0.
vector(word size): t(0) { reset(size); }
Inicjalizuje rozmiar tablicy na size.
~vector() { delete [] t; }
Usuwa tablicę.
word size() const { return size; }
Zwraca rozmiar tablicy.
T &oprerator[](word i) const { return const_cast<T&>(t[i]); }
operator T*() const { return const_cast<T&>(t); }
Operatory ułatwiające użycie tablicy. W przypadku kompilatorów bez operatora const_cast należy zastosować zwykłe rzutowanie.
dynarray2<T>T ** t;
Trzyma tablicę wskaźników na pierwsze elementy wierszy tablicy. t==0 oznacza pustą tablicę.
word fdx;
word fdy;
Przechowują rozmiary tablicy.
dynarray2() : t(0) {}
dynarray2(word dy, word dx);
Inicjalizują tablicę.
~dynarray2() { if (t) delete t[0]; delete t; }
Zwalnia pamięć przeznaczoną ta tablicę. Najpierw musi zwolnić pamięć zaalokowaną na trzymanie elementów tablicy (wskaźnik na ta tablicę jest przechowywany w t[0] (jeżeli t nie jest 0)). Następnie musi zwolnić tablicę wskaźników na pierwsze elementy wierszy.
void alloc(word dy, word dx);
Alokuje pamięć pod tablicę o rozmiarach dy wierszy na dx kolumn. Na początku należy zaalokować dy wskaźników na T, i przypiąć adres tej pamięci to zmiennej składowej t. Następnie należy zaalokować dx*dy elementów typu T, i adres przypisać to t[0]. Teraz trzeba wpisać adresy w wektor t. W pętli dla i od 1 do dy-1 ustawiamy t[i] na t[i -1] + dx.
word dy () const { return fdx; }
void dx () const { return fdy; }
Zwracają rozmiary tablicy.
void reset (word dy, word dx);
Ustawia nowy rozmiar, wszystkie poprzednie dane są tracone. Najpierw dealokuje pamięć zaalokowaną poprzednio, a potem używa alloc.
void resize (word dy, word dx);
Ustawia nowy rozmiar, dane są kopiowane. Tworzy tymczasową zmienną, aby przechować t, wywołuje alloc, a następnie kopiuje zawartość poprzedniej tablicy linia po linii, tak, że każda linia starej tablicy jest w innej linii nowej tablicy. Na końcu trzeba zwolnić pamięć poprzedniej tablicy.
T* oprerator[](word dy) const;
operator T**() const;
T& operator()(dword offset) const;
Operatory ułatwiające dostęp do danych.
To samo co dynarray2, tyle, że tylko dolny trójkąt macierzy, bez diagonalii. Trzeba zmienić pętlę w alloc, tak aby ustawiała odpowiednie adresy. I należy alokować odpowiednią ilość pamięci.
mapvector<mapobj *> mapobjs;
Lista obiektów na mapie.
word sx;
word sy;
word sdx;
word sdy;
Pozycja i rozmiar okna wyświetlanego na ekranie.
word vx;
word vy;
Pozycja na mapie pierwszego widocznego pixela na ekranie.
screen * scr;
Wskaźnik na ekran, na którym ma być wyświetlana mapa.
class plotter;
Klasa rysująca mapę na ekranie.
map() : scr(0) {}
Konstruktor domyślny.
map(word dx, word dy, screen *s)
Ustawia ekran na podany oraz ustawia rozmiary tablicy na podane. Otacza mapę ścianami.
~map();
Dealokuje pamięć przeznaczoną na mapobje.
inline void insobj(mapobj *);
Dodaje nowo zaalokowany dynamicznie mapobj do listy. Dealokacją pamięci zajmie się obiekt map. Tylko dynamicznie zaalokowane obiekty!
inline void delobj(mapobj *);
Usuwa podany obiekt z mapobjs i dealokuje pamięć.
void draw();
Rysuje mapę na podanym ekranie. Wykonuje to poprzez w pętli stworzenie tymczasowego obiektu klasy map::plotter i wywołania funkcji screen::put(word, word, word, map::plotter) dla każdego wiersza z odpowiednimi parametrami, tak aby mapa wyświetliła się w oknie określonym przez zmienne sx, sy, sdx, sdy od miejsca vx, vy. Te parametry to sy+numer_wiersza_okna, sx, sdx. Obiekt klasy map::plotter musi mieć przekazany parametr offset równy (vy + numer_wiersza_okna)*dx + vx, np.:
scr->put(sy + i, sx, sdx, plotter(this, (vy+i)*dx+vx));
inline void setclip(word sy, word sx, word sdy, sdx);
Ustawia zmienne sy, sx, sdy, sdx. Nie przerysowuje mapy ani jej nie kasuje.
inline void setpos(word vx, word vy);
Ustawia zmienne vx, vy. Nie przerysowuje mapy ani jej nie kasuje.
inline screen::attr getattr(dword offset);
Zwraca atrybuty pixela o podanym offsecie na mapie (offset to kolejny numer pixela, pixel o pozycji y, x na mapie ma offset równy y*dx+x). Ta funkcja uwzględnia mapobje. Kolory i znaki do ustalenia przez implementatora.
mapobjword fx;
word fy;
Przechowują pozycję mapobja na mapie.
map &parent;
Mapa, na której znajduje się obiekt. Nie można jej zmienić.
void mapobj (word x, word y, map &parent) : fx(x), fy(y), parent(parent) {}
Jedyny konstruktor obiektu. Ustawia odpowiednie zmienne.
virtual ~mapobj()
Wirtualny destruktor, ponieważ obiekty będą niszczone jako mapobje.
word x() { return fx; }
word y() { return fy; }
Funkcje dające dostęp do pozycji mapobja.
virtual attr paint() =0;
Wirtualna funkcja, która zwraca wygląd obiektu.
map &map() const;
Pozwala na dostęp do mapy, na której znajduje się obiekt. Nie powinno się w obiektach, które dziedziczą po mapobj, używać zmiennej parent. Należy używać tej funkcji.
movmapmapobj* actobj;
Wskaźnik na obiekt, który powinien być zawsze widzialny. Jednocześnie reprezentuję on drugą warstwę - może on być na polu z innym mapobjem. Wtedy on jest widzialny, a nie obiekt pod nim.
enum direction { up, right, down, left };
Ten typ reprezentuje kierunek, w jaki się może poruszyć movmapobj.
~movmap() ;
Jego zadaniem jest dealokacja pamięci actobja.
bool adjust();
Zapewnia, że actobj jest widzialny, poprzez ustawienie odpowiednie zmiennych vx i vy. Powinno być tak, że jeżeli actobj znajduje się za blisko od którejś krawędzi okna ekranowego (tj. bliżej niż delta), to należy ustawić na wartości najmniej różniące się od aktualnych, ale takie, aby actobj był w odległości delta od krawędzi. Zwraca true, gdy vx lub vy się zmieniło.
void setactobj(mapobj *actobj);
Ustawia actobj.
bool moveobj(movmapobj *, direction dir);
Porusza podanym obiektem w danym kierunku, zmieniając jego współrzędne. Jeżeli nie jest to obiekt z drugiej warstwy, to trzeba uaktualnić tablicę przechowującą mapę oraz sprawdzić, czy nie będzie dwóch obiektów na jednym polu. Wywołuje adjust, jeżeli podany obiekt jest actobjem; jeżeli zwróciło true, to przerysowuje całą mapę. W przeciwnym wypadku aktualizuje rysunek na ekranie poprzez przerysowanie dwóch zmienionych pixeli. Zwraca true, gdy poruszenie się udało.
Ta funkcja powinna również opóźniać wykonanie programu tak, aby użytkownik mógł obserwować ruch robota na ekranie. Opóźnienie powinno być ustawialne z klawiatury właśnie w trakcie trwania tej pauzy. Czas pauzy nie powinien zależeć od szybkości komputera, co wymusza korzystanie z zegara. Można do tego użyć np. funkcji GetTickCount z Windows API lub obiektu klasy Timer z biblioteki Borland C++ 3.1.
mapobj *checkpos(mapobj *) const;
Zwraca obiekt pierwszej warstwy, który jest na tym polu, co argument, lub 0. W szczególności dla obiektów pierwszej warstwy zwraca podany argument. Po prostu zagląda do odpowiedniej komórki tablicy przechowującej mapę, a następnie do tablicy mapobjs.
virtual void draw();
Najpierw wywołuje map::draw, a potem rysuje actobj - czyli drugą warstwę w odpowiedniej pozycji w oknie na ekranie.
movmapobjmovmapobj(word x, word y, movmap *parent) : mapobj(x, y, parent) {}
Jedyny konstruktor. Przekazuje do mapobj odpowiednie wartości. Należy zwrócić uwagę, że movmapobj może być tylko na mapie movmap.
movmap &map () const { return static_cast<movmap &>(parent); }
W związku z tym możemy spokojnie przedefiniować funkcję map, aby zwracała referencję do movmapa, konwertując statycznie zmienną map. Jeżeli kompilator nie wspiera operatora static_cast, używamy zwykłego rzutowania.
typedef movmap::direction direction;
Aby było wygodniej, definiujemy typ direction w movmapobj.
bool move(direction dir) { return map().moveobj(this, dir); }
Porusza obiektem używając movmap::move, jeżeli udało się ruszyć, i tylko wtedy, zwraca true; przerysowuje mapę.
mapobj *checkpos() const { return map().checkpos(this); }
Zwraca mapobj, który znajduje się w pierwszej warstwie na aktualnej pozycji lub 0. Używa map::checkpos.
robomap
word secchkpntcount;
Przechowuje liczbę zabezpieczonych checkpointów.
word chkpntscount;
Przechowuje liczbę wszystkich checkpointów.
void checkednotify(checkpoint *);
Ta funkcja powinna być wywoływana po zabezpieczeniu checkpointa, implementacja aktualizuje zmienne składowe, tj. secchkpntcount.
friend void checkpoint::enternotify(const roboobj &co);
Pozwala klasie checkpoint na wywołanie funkcji checkednotify.
robomap (roboobj *robo, word dx, word dy, screen *scr);
Konstruktor: parametr robo to robot, który będzie zabezpieczał checkpointy. Powinien on być jednocześnie ustawiony jako actobj. Inicjalizuje secchkpntcount i chkpntscount na 0.
bool allchecked() const { return secchkpntcount == chkpntscount; }
Zwraca true ó gdy wszystkie checkpointy zostały zabezpieczone.
bool generatecheckpoint(word tries);
Próbuje tries razy losować pozycję na mapie. Sprawdza, czy na niej jest pusty pixel. Jeżeli tak, tworzy nowego checkpointa z odpowiednim numerem, ustawia go tam i wychodzi. Zwraca true ó udało się wstawić checkpointa. Zwiększa chkpntscount o jeden.
roboobjinline bool securecheckpoint(/* out */ checkpoint *&co);
Zabezpiecza checkpoint na aktualnej pozycji. Zwraca true, jeżeli został zabezpieczony. W parametrze co zwraca checkpoint na aktualnej pozycji lub 0, jeżeli nie ma.
Najpierw należy wywołać funkcję checkpos i przechować wynik. Jeżeli jest niezerowy to sprawdzamy, czy wskazuje na obiekt klasy checkpoint. Jeżeli tak, to należy wywołać funkcję checkpoint::enternotify, oraz do parametru przypisać otrzymany wskaźnik. W przeciwnym wypadku należy zwrócić false.
Jeżeli nie ma RTTI w kompilatorze (dynamic_cast), to należy zrobić wirtualną funkcję zwracającą id typu w klasie mapobj, i na jej podstawie wiedzieć, czy dany mapobj jest checkpointem.
roboobj(word x, word y, robomap &parent) : movmapobj(x, y, parent) {}
Jedyny konstruktor. Widzimy, że roboobj może być tylko na mapie typu robomap...
robomap &map () const;
… więc możemy spokojnie dokonać konwersji parent na robomap&....
checkpointword number;
Przechowuje numer checkpointa.
roboobj(word x, word y, robomap &parent, word number) : movmapobj(x, y, parent), number(number) {}
Jedyny konstruktor. Ustala odpowiednie zmienne. Checkpoint może być tylko na robomapie.
int enternotify(const roboobj &robo);
Informuje checkpoint o wejściu nań robota, ale powinien to sprawdzić. Zwraca -1 jak jeszcze nie został zabezpieczony, jak został to swój numer. W implementacji po sprawdzeniu pozycji oraz tego, czy wszystkie poprzednie checkpointy zostały zabezpieczone (number == robomap::secchkpntscount) wywołuje robomap::checkednotify.
robomap &map () const;
Konwersja parent na robomap.
robostruct edge;
Struktura identyfikująca krawędź łączącą dwa checkpointy.
vector<byte> mem;
Mapa pamiętana przez robota, jej rozmiar poziomy i pionowy jest dwa razy większy niż rzeczywistej mapy, po zakończeniu przeszukiwania mapy i znalezieniu wszystkich checkpointów może zostać zwolniona.
vector<checkpoint *> chkpnts;
Przechowuje wskaźniki do już odkrytych i niezabezpieczonych checkpointów; indeks w tej tablicy jednoznacznie identyfikuje checkpointa.
word unsecchkpntscount;
Liczba niezabezpieczonych checkpointów po przeszukaniu mapy.
dynhalfarray2<path> paths;
Przechowuje ścieżki pomiędzy checkpointami.
vector<word> visited;
Wektor używany przy przeszukiwaniu w głąb.
tree t;
Zmienna pamiętająca minimalne drzewo rozpinające.
stack<word> s;
Stos używany przy przeszukiwaniu w głąb.
inline bool gotocheckpoint(word source, word dest);
Funkcja przechodzi od jednego checkpointa do drugiego po znalezionej ścieżce w tablicy paths. Aby nie trzymać dwóch kopii jednej ścieżki (od checkpointa x do y i odwrotnej), chodzimy po niektórych ścieżkach od tyłu.
Sprawdzamy, czy dest < source. Jeżeli tak to wywołujemy funkcję gotopath z parametrem paths[source][dest]. Jeżeli dest > source to wywołujemy funkcję gotorevpath z parametrem paths[dest][source]. Jeżeli dest == source to zwracamy true, inaczej zwracamy wartość zwróconą przez gotopath.
inline word delta(word source, word dest);
Zwraca odległość między checkpointami, wyciągniętą z tablicy paths (tj. rozmiar tej tablicy). Odpowiedni element ustalamy tak jak poprzednio.
bool gotopath(const path &co);
Przechodzi robotem po podanej ścieżce. Odczytuje kolejno ze ścieżki kierunki, w którym ma się poruszyć i czyni to. Nie sprawdza, czy weszło na jakiś obiekt. Jeżeli nie udało się wejść na jakiś pixel z powodu ściany, funkcja zwraca false.
bool gotorevpath(const path &co);
To samo co poprzednia funkcja, tylko przechodzi ściezkę od tyłu.
void play ();
Główna pętla działań robota. Ma na celu zabezpieczenie wszystkich checkpointów.
robo(word x, word y, robomap &parent) : roboobj(x, y, parent) {}
Konstruktor. Przekazuje parametry do konstruktora klasy bazowej.
map::plottermap *m;
Przechowuje wskaźnik na mapę, która będzie rysowana.
dword baseoffset;
Offset bazowy. Jest to offset w tablicy tego pixela, który będzie narysowany jako pierwszy w podanej w wywołaniu screen::put pozycji.
plotter(map *m, dword baseoffset) : m(m), baseoffset(baseoffset) {}
Konstruktor ustawiający parametry.
inline screen::attr operator()(word offset) const { return m->getattr(baseoffset + offset); }
Operator pozwalający używać obiektu jak funkcji. Zwraca atrybuty tego pixela, który jest w tym samym wierszu, co pixel bazowy i w kolumnie o offset oddalonej na prawo od bazowej.
Implementacja wywołuje po prostu map::attr z parametrem równym sumie offset i baseoffset.
screenword fdx;
word fdy;
Rozmiar ekranu w pixelach
struct attr {
char ch; // znak
byte cl; // kolor
attr(ch, cl): ch(ch), cl(cl) {}
};
Struktura przechowująca atrybuty pixela.
word dx() const { return fdx; }
word dy() const { return fdy; }
Zwracają rozmiary ekranu.
virtual bool open();
Inicjalizuje ekran do użycia.
virtual void close();
Zamyka ekran.
virtual void put (word y, word x, attr pixel) =0;
Wypełnia podany pixel podanymi atrybutami.
virtual void put(word y, word x, word dx, map::plotter &) =0;
Wypełnia dx pixeli w wierszy y zaczynając od pixela w kolumnie x atrybutami podawanymi przez obiekt klasy map::plotter. Atrybuty i+x pixela w wierszu y otrzymujemy wywołując map::plotter::operator() z parametrem i.
queueword beg;
Index tego elementu tablicy, który jest pierwszy do zdjęcia
word end; I
Index tego elementu tablicy, w którym się powinno dostawić nowy element
queue();
Konstruuje kolejkę o rozmiarze 0.
queue(word size);
Konstruuje kolejkę o rozmiarze size.
ins(const T &co);
Wstawia nowy element na kolejkę.
T pop();
Zdejmuje element z kolejki i go zwraca.
T *begin()
Zwraca początek tablicy elementów na kolejce, czyli początek tablicy przesunięty o beg.
Należy zakodować jedną z klas dosscreen, winconscreen lub linuxscreen, używając funkcji specyficznych dla danego systemu operacyjnego. W przypadku dosscreen należy zapisywać dane bezpośrednio do pamięci.
Wyjaśnienia wymaga także konstrukcja funkcji screen::put(map::plotter &). Chodzi o to, aby nie trzeba było wywoływać funkcji wirtualnej dla każdego pixela oraz żeby nie trzeba było buforować całych linii w pamięci przed przesłaniem ich na ekran. Niestety, aktualnie kompilatory nie wspierają wirtualnych funkcji template'owych, więc nie da się tego zrobić bardziej uniwersalnie. Chociaż to tez nie jest najlepiej, ale zapewnia maksimum szybkości (przy inlinowaniu).
Klasa map powinna wspierać wyświetlanie tylko pewnego okna na mapę o wielkości ekranu komputera. Zmienne map::vx i map::vy oznaczają współrzędne na mapie pierwszego widocznego pixela na ekranie. Po każdym ruchu robota ekran powinien być aktualizowany. Jeżeli potrzebne jest przesunięcie okna (jeżeli robot przejdzie za blisko krawędzi ekranu), należy narysować całą mapę od początku, w przeciwnym wypadku wystarczy odświeżyć tylko zmienione pixele. Na ekranie powinna być odzwierciedlona różnica między odwiedzonymi i nieodwiedzonymi pixelami. Także zabezpieczony checkpoint powinien wyświetlać swój numer. Powinna być widoczna różnica pomiędzy zabezpieczonym i niezabezpieczonym checkpointem.
Typ screen::attr ukrywa atrybuty pojedynczego pixela ekranu. Są to: znak w kodzie ASCII i kolor znaku oraz tła - znaczenie specyficzne dla implementacji - jeżeli zaistnieje potrzeba, można zmienić typ screen::attr tak, aby lepiej odzwierciedlał możliwości prezentacji na ekranie, np. w trybie graficznym.
Do klasy screen można dodać funkcje obsługujące funckje specyficzne dla implementacji, np. wypisanie ciągu znaków na określonej pozycji, wczytanie ciągu znaków.
W przypadku implementacji w trybie tekstowym należy użyć trybu 80x50 znaków.
Poniżej znajduje się kilka rysunków pokazujących różne strategie chodzenia robota. Pierwsza z nich jest zbliżona do algorytmu rzeczywiście zastosowanego, w pewnym momencie pominięto ściany ograniczające mapę.
Druga strategia przechodzi zawsze ściany równoległe do krawędzi pierścieni przed szukaniem najbliższego nieodwiedzonego pixela. Ta wersja nie została zaimplementowana.
Ten dokument znajduje się pod adresem
http://mar.prv.pl/education/piwut.htmoraz
http://mar.prv.pl/education/piwut.doc.